|
|
|

INTRODUCTION
I created this website in order to help demistify the science of knowledge representation (KR for short) for all who are interested in this still largely underappreciated scientific field. Representing knowledge, in itself, is not a very difficult thing to understand: It is no mystery that computers are a great way to store and retrieve information. But have you ever wondered where things currently stand with the science behind computer information? Is the way we currently use information on computers about as good as it can be? ...Or, can we expect that there are major advancements still ahead of us?
Anyone who looks closely at the way we currently store and use information with computers will find that our methods are, at best, still rather crude.
But I think, additionally, that these limitations are fixable and that major changes are awaiting us in the way we represent and use knowledge electronically- although I will try to show that we have already had a couple of revolutions of knowledge representation in the past, an entirely new revolution (and probably the largest) is looming just over the horizon!
I hope that after you read this essay you might agree that some inevitable changes lie ahead of us, but I also hope this essay will provide you with a lot of practical, nitty gritty details at how modern knowledge representation systems work that can be hard to pick up from other sources- This will help you anticipate any new developments in this field if the do indeed happen in our future.
The 10,000 Foot View
Because the science of KR touches on so many fields of thought, we can easily become confused if we can't appreciate the big picture of where we've been with KR and where we will most likely be heading. To do this, let's take a look at the major players that have been the driving forces in modern information systems. By players, I mean that there are some distinct communities of computer users that have unique philosophies and can be represented by an iconic idea, or archetype. For the sake of this primer, we can classify all computer users as belonging to one of three main archetypes:

The Guy In The Garage

The Writer

The Scientist
If we look at the history of computers, it appears that these three archetypes have been (and potentially will be) triggers of revolutions in how we use electronic information. The term revolution, for sake of this essay, refers to a major shift in the way computers can be used to use information that has a tangible, everyday effect on mainstream society, with major financial and philosophical effects on how people produce and consume computerized information. Let's take a look at some of these three archetypes a little more closely:
The Guy In The Garage

In the early days, computers were expensive and had little computing power. Hence, many accommodations had to be made by computer operators in order to get these early machines to do anything useful at all. At many universities, a new breed of computer engineer appeared, able to overcome the limitations of these machines by their willingness to compromise their methods and approaches for the sake of pragmatism- People like him, the proverbial computer hacker, began to develop things such as FORTRAN compilers, file systems, etc- the nuts and bolts of modern computer software. People like him also started the early companies like Apple Computers- leading to the myth of the Guys in the Garage. But in terms of knowledge representation, the most important idea contributed by The Guy In The Garage was his invention of the relational database managment system (RDBMS for short).
The RDBMS sparked the first major revolution in electronic knowledge representation: In the late seventies, average people began to directly encounter the work of computer systems: machines began to print airline tickets, give account information at bank tellers, and tracked customers, orders and inventories at many companies. Although some of the theory behind the performance of RDBMSes was based on advanced scientific theories (such as tuple calculus and others), when used as a tool to represent knowledge, RDBMSes require little advanced scientific understanding: They are incredibly effective storage tools, but are also crude and limiting in terms of their expressiveness. As the guy in the garage might say: "It ain't pretty but it works!"
The Writer

Although The Guy In The Garage was able to accomplish major feats with early computer systems, his designs had one very serious limitation: Most information that was entered into a computer system had to be entered in a way that the computer could "understand": in other words, a computer user had to enter in the airline tickets, bank orders, or factory widgets in a simplistic, computer-friendly manner. Early systems worked this way because computers back then were uncommon and networks were small, so most data entered into computers was entered "for" the computer, not for other people. This meant that a lot of people who knew a great deal about many things (but had little to do with computers) had not yet benefited from the world of computer science... until, of course, the advent of the second computer revolution: The Internet Era.
All of a sudden, it didn't matter if a computer couldn't "understand" knowledge about art, medicine, literature, or other fields: By letting humans directly interact through the medium of the internet, experts in different fields could communicate in raw text or pictures directly with each other. In this new era, people who had expertise in specific fields could write their knowledge into crude computerized web pages that other people could easily access. By transforming the computer from an end in itself into a medium of communication, a far larger community of non-technical "domain experts" could now benefit from computers that were previously useful to only the smaller community of the technical elite. All of a sudden, the amount of actual knowledge stored on computers exploded, although in a rather chaotic and unorganized fashion.
But There's More!
There is an important twist to the second KR revolution that, in a way, makes it far more important than the first. This is because the two different personalities that became part of the computer era could now interact in many different ways and bounce ideas off of each other in ways that were previously not possible. We can illustrate this in a somewhat fanciful way by creating a gradient between The Guy In The Garage and The Writer:
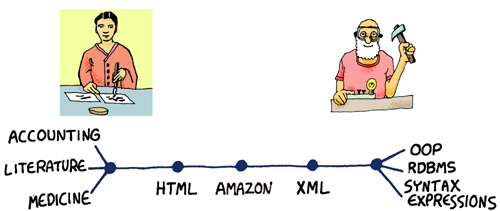
This diagram illustrates the existence of two different communities of people enabled many new ideas that were previously obscure or impractical to be developed; people were able to develop hybrid ideas that borrowed both from the world of The Guy In The Garage (and his simple but highly structured, computer friendly data) and The Writer (and his rich, complex, but highly unstructured data). These hybrid ideas were essentially new forms of data that contain elements that are structured as well as unstructured. In a way, this new revolution in knowledge amplified its effects through a bridge it formed between these two archetypes, producing new concepts like search engines, markup languages, and others. In short, there was (to use the old ninties cliche) synergism.
OK... So where's The Scientist in all This?

Missing in this whole discussion is The Scientist. Although she played a critical role in developing the technology that made computers possible in the first place, so far she has played only a very minor role in the world of computer software or knowledge representation: When you write a term paper in a word processor, read your email, or play solitaire, very little of what we call "advanced science" comes into play: To write such software, a programmer needs little or no knowledge of things like integral calculus, theorem proving , general relativity, linguistics, or other sciences.
No one really expected that things would end up this way: It would have made much more sense that the world of computer science should be "ruled" by advanced scientists, but this is just not what happened. Although scientists have of course made many important advances to the world of computers, when it comes to software and KR their impact has been miniscule compared to that of the hackers and domain experts we discussed earlier. Although scientists have put much effort into computer KR in the last few decades, many people have found the results rather disappointing (one dramatic example was the AI winter). So where does The Scientist fall in the scheme of things, then?
In short, it turns out that the job of The Scientist when it comes to information and computers has simply been more difficult than was originally expected- partially, it may be due to the complexity of software in itself, but mainly, I think, it is due to the fact that a revolution of any sort requires the participation of many people and that, in this case, the limitations of human psychology have prevented the true science of knowledge in software to really take hold as was originally expected. But, still, I think the future of The Scientist is secure: The Third Computer Revolution will be The Revolution Of The Scientist!
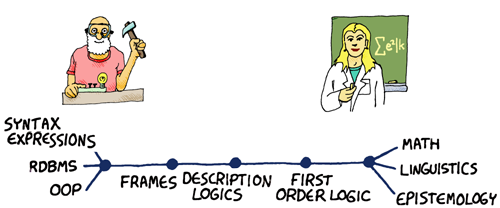
The main goal of this primer on knowledge representation will be to look at this Revolution of The Scientist and how it will come about. In my opinion, most of the seeds that will trigger this revolution are already in place. Additionally, these ideas can again be mixed with ideas from the other archetypes... For instance, some of these ideas can be blended with ideas out of the garage:
Whereas other ideas are more compatible with the knowledge of writers and domain experts:
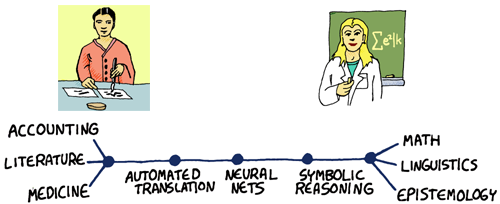
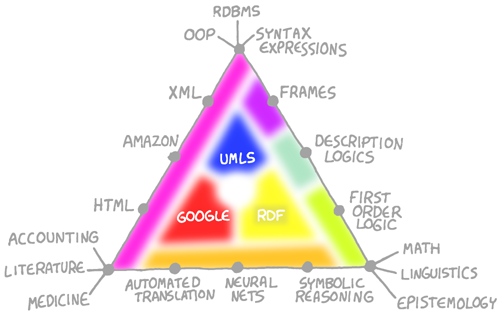
These diagrams are of course simplistic, but they allow us to express something basic about how such disparate ideas on knowledge relate to each other... Furthermore, we can place all of them into a triangle... Behold!
Conrad's
Somewhat Accurate Triangle of
Knowledge Representation&trade
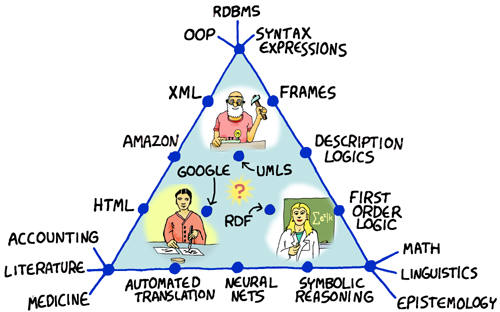
Using this triangle, we can display all the major ideas in knowledge representation as a function of their pragmatism, scientific rigor, and accessibility to domain experts- The oldest ideas lie at the corners, while more recent ideas appear along the sides. Only in more recent times is software slowly beginning to fill in the areas in the center of this triangle. For the rest of this primer, let us dissect this triangle into parts and analyze every corner of the world of KR:
SECTION I- The Many Sides Of KR
 How Scientists Think About Knowledge How Scientists Think About Knowledge
 Why We Need Science Why We Need Science
 Making Data Smarter With Frames Making Data Smarter With Frames
 Description Logics: A Blend of Logic and Pragmatism Description Logics: A Blend of Logic and Pragmatism
 What Has AI Taught Us About Knowledge? What Has AI Taught Us About Knowledge?
SECTION II- Technology Portends The Future!
 RDF and The Semantic Web RDF and The Semantic Web
 The Guys In The Garage and the UMLS The Guys In The Garage and the UMLS
 The Secret World of Advanced Search Technology The Secret World of Advanced Search Technology
 The Soft And Chewy Center! The Soft And Chewy Center!
Why We Need Science >>
Special Thanks to Scott Hollington, M.D. and Lauren Hancock for their help in making this primer possible.

This work is licensed under a
Creative Commons License.
|
|
|
|